Ciencia & Tecnología
Latam-GPT, inteligencia artificial con ojos latinoamericanos
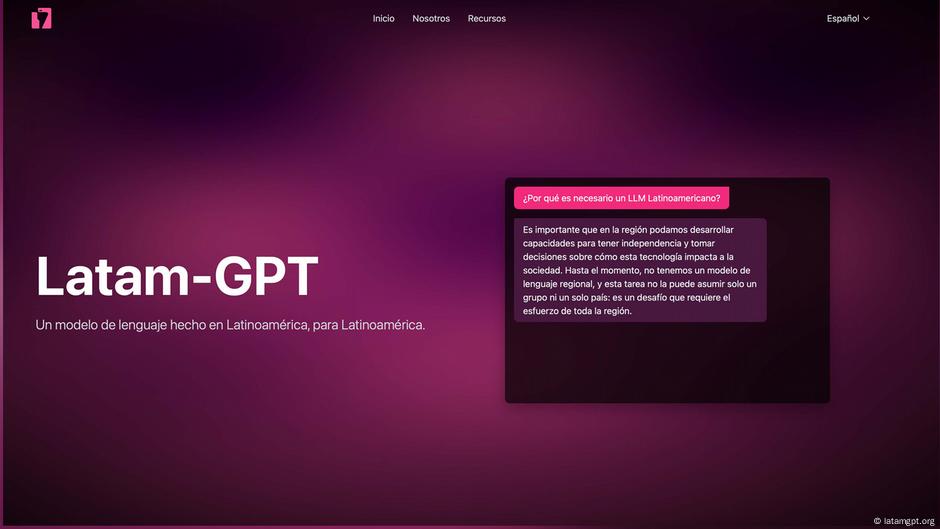
ChatGPT y DeepSeek tendrán un nuevo rival muy pronto. Esta vez, la competencia no viene de EE.UU., y tampoco es china ni europea. Se llama Latam-GPT y es latina, pero eso no es lo único que la distingue del resto.
ChatGPT y DeepSeek tendrán un nuevo rival muy pronto. Esta vez, la competencia no viene de EE.UU., y tampoco es china ni europea. Se llama Latam-GPT y es latina, pero eso no es lo único que la distingue del resto.
El Centro Nacional de Inteligencia Artificial en Chile (CENIA) trabaja desde hace 2 años en el desarrollo de una inteligencia artificial ‘made in’ Latinoamérica. Entrenada exhaustivamente con datos de fuentes contrastadas, Latam-GPT se está gestando lentamente para su lanzamiento a mediados de este año y cuenta con el apoyo de muchos otros países de América Latina. El modelo de lenguaje extenso (LLM) nacido en Chile podría cambiar la forma en que Latinoamérica ve la inteligencia artificial, pero también la forma en que la inteligencia artificial ve a Latinoamérica.
Colaboración y soberanía
Latam-GPT es un proyecto en fase de construcción que busca crear un modelo de inteligencia artificial abierto, gratuito y, principalmente, colaborativo. La empresa que lo desarrolla, CENIA, es una corporación privada sin ánimo de lucro que trabaja con gobiernos, universidades y otras instituciones latinoamericanas para impulsar el desarrollo de la inteligencia artificial en la región.
Álvaro Soto, director de CENIA, plantea la creciente ola de inteligencia artificial como un reto para América Latina y cree que «Latinoamérica ha estado un poco más en la periferia de las revoluciones tecnológicas más recientes”. Soto defiende que si la región quiere «ser parte [de la revolución de la IA], tenemos que generar las capacidades; tenemos que estar en control y en posición de poder investigar, adaptar y modificar estos modelos de acuerdo a necesidades locales”.
La importancia de ganar soberanía y poder de decisión desde Latinoamérica es, según Soto, un motivo para impulsar una IA latina, pero no el único. Para el director de CENIA, «hay un poco de soberanía en eso, pero más que soberanía, […] es poder colaborar con otra gente en otras partes del mundo que desarrolle este tipo de modelos; en Europa, EE.UU… Donde sea que haya posibilidades de poder colaborar, pero en esa colaboración también tener la posibilidad de conocer y aportar como un actor activo, no tan pasivo, en el desarrollo de la tecnología”.
Uno de los principales objetivos tras la creación de Latam-GPT, así como de otras iniciativas promovidas por CENIA (por ejemplo, la creación de traductores en línea para lenguas nativas latinoamericanas), es el de impulsar el desarrollo tecnológico en la región. Funcionar como una suerte de «facilitador», en palabras de Soto, para que las compañías y los emprendimientos de Latinoamérica puedan acceder libremente a ese tipo de innovación y usarlo para seguir ampliando los avances tecnológicos locales.
Además, Soto considera que modelos como ChatGPT, DeepSeek o Gemini han sido entrenados mayormente «con datos en inglés y que vienen principalmente del hemisferio norte. Y eso hace que, cuando tú quieras usarlos y requerir información más específica, de Latinoamérica, por ejemplo, muestren vacíos o alucinen”. Es por eso que la iniciativa detrás de Latam-GPT vio una brecha en la oferta tecnológica y, con ella, la posibilidad de «generar un modelo que conozca de manera más cercana [a Latinoamérica] y sea entrenado con datos de Latinoamérica” añade Soto.
Modelo latino vestido a medida
En lo que a datos se refiere, el chatbot latino ha sido entrenado siguiendo procesos distintos a la mayoría de modelos de éxito. Soto pone de relieve las diferencias en cuanto a recursos disponibles, pero también en cuanto a los métodos utilizados: «Es un proyecto que es difícil de poder hacer en un grupito pequeño. Las grandes empresas lo hacen, pero tienen muchas espaldas de recursos. Pero en Latinoamérica no contamos con eso y la forma en que se ha hecho es básicamente colaborativa. Uno de los recursos fundamentales para que estos modelos sean exitosos es poder juntar datos de gran envergadura. Las empresas tecnológicas lo han hecho principalmente escrapeando [un proceso automatizado de recopilar información] la web de forma masiva. En nuestro caso, lo hemos hecho, de alguna manera, tocando puertas por toda la región”.
Con «tocar puertas” por la región, Soto se refiere a una forma paulatina de recopilar información con el apoyo, contacto directo y consentimiento de universidades, ministerios y fundaciones de múltiples países latinoamericanos, así como la participación de desarrolladores, investigadores y profesionales en IA de la región. El uso de bancos de datos masivos como RedPajama y el trabajo con la comunidad de expertos en PLN (procesamiento de lenguaje natural) SomosNLP, han sido clave para la recopilación de datos y el entrenamiento de Latam-GPT.
El desarrollo colaborativo parte de una iniciativa que surge de abajo hacia arriba o ‘bottom-up’, como la describe el director de CENIA, pero también cuenta con apoyo ‘top-down’ o, de arriba hacia abajo. Latam-GPT ha contado con el aporte de recursos de más de 30 organizaciones de distintos países, entre las que destacan el gobierno chileno, por la financiación y los avances en legislación de IA, y universidades como la de Tarapacá, por la prestación de recursos e infraestructura impulsada con energía renovable.
Además de destacar cómo los recursos y la financiación externa han ayudado a levantar la iniciativa, Soto también menciona que la base algorítmica sobre la que se construye Latam-GPT es una versión afinada de otro modelo de inteligencia artificial previamente existente llamado Llama 3, desarrollado por el giganteMeta y de código abierto. El desarrollo del LLM latinoamericano se consolidaría así como una versión personalizada y adaptada de otro preexistente, y no como uno creado desde cero, como sí pueden haberlo sido modelos como DeepSeek o ChatGPT.
Latam-GPT contará en su primera versión liberada con «70.000 millones de parámetros y 2 trillones de tókens”, y hablará con fluidez español, portugués e inglés, según compartió Soto, que también reconoce que el desarrollo a lo largo de estos últimos 2 años «tardó mucho”. Tras la larga espera, Latam-GPT funcionará inicialmente como un chatbot de texto al uso, que no cierra las puertas a seguir implementando más funcionalidades de cara a futuro, y que será lanzado al público por primera vez en julio de este 2025.
(ers)
Deutsche Welle: DW.COM – Ciencia y Tecnologia

































